
OnTrack Voice Verification Design Document
Author Information
- Author: ShaeChristmas
- Team: OnTrack - Voice Verification
- Team (Delivery and/or Product) Lead: Shae Christmas
Document Summary
- Documentation Title: Voice Verification Design Document
- Documentation Type: Technical
- Documentation Information Summary: Design Document detailing implementation of Voice Verification system in the OnTrack Project
Document Review Information
- Date of Original Document Submission to GitHub: 14/09/2022
- Documentation Version: 1.1
- Date of Previous Documentation Review: 30/09/2022
- Date of Next Documentation Review: to be decided
Key Terms
CLI: Command Line Interface; Interacting with something through the terminal
Docker Container: A small program contained inside a virtual machine. The containerisation program used is called Docker.
RabbitMQ: A message broker that allows for the communication between different programs.
Key Links/Resources
- OnTrack Overseer Repository
- OnTrack Web Repository
- OnTrack API Repository
- OnTrack Voice Verification Python Container Repository
- OnTrack Voice Verification API Repository
Contacts for further information
See Thoth Tech Handbook.
Related Documents
Delivery Description
OnTrack as a platform allows for students to track assessments for enrolled subjects, and submit their work once completed. Audio submissions have been a substitute for in-person discussions in recent years.
The OnTrack Voice Verification system aims to verify audio submissions, to ensure that the speaker in the submission is the correct student.
This system would be implemented inside the existing OnTrack Project, and integrated into OnTrack by using the pre-existing audio submission system.
Problem Statement
When submitting an assessment with an oral component, the student may take advantage of the OnTrack audio submissions system.
However, any audio file may be submitted through this system; it is not verified at any stage in the current OnTrack implementation. Contract cheating or other methods of cheating could be used, and would not be picked up by the system automatically.
A possible method to cheat by taking advantage of the pre-existing system would be to pay someone else to answer audio questions. As no verification process is taking place, tutors may not identify that the person speaking is not the student who is being assessed.
A verification system for testing audio submissions against a baseline audio sample would make this type of cheating more difficult.
The voice verification system would give a confidence in the speakers identity, which could then be verified by an assessor if necessary.
As such, this allows for greater verification of submissions, and ensuring that cheating using the audio submission system can be minimised.
Current Works
The current voice verification system is not linked to the OnTrack architecture. Instead, the system is implemented as a Docker Container, that can accept audio inputs, and produces a confidence variable with certainty of the speakers identity.
At this stage, the system receives a known sample, and a new audio file. These must be manually submitted to the container through the CLI.
As such, a system to link the existing Docker container to the OnTrack system must be implemented for automatic verification and display of results.
Design
The Voice Verification Architecture uses similar to a system in place within OnTrack called OnTrack Overseer.
When an audio file is received in the database, a trigger is sent to the Message Queue system that the Voice Verification architecture employs. This system uses RabbitMQ as a message queue, to send files to be verified to the main Voice Verification container. This container uses Deep Speaker verification to test the new file against the baseline file collected for that student. Then, the confidence value appended to the message on the message queue, and saved in the database.
After the confidence value is saved in the database alongside the file, this can be retrieved by the system. This retrieval takes place when the file is requested for marking.
Architecture
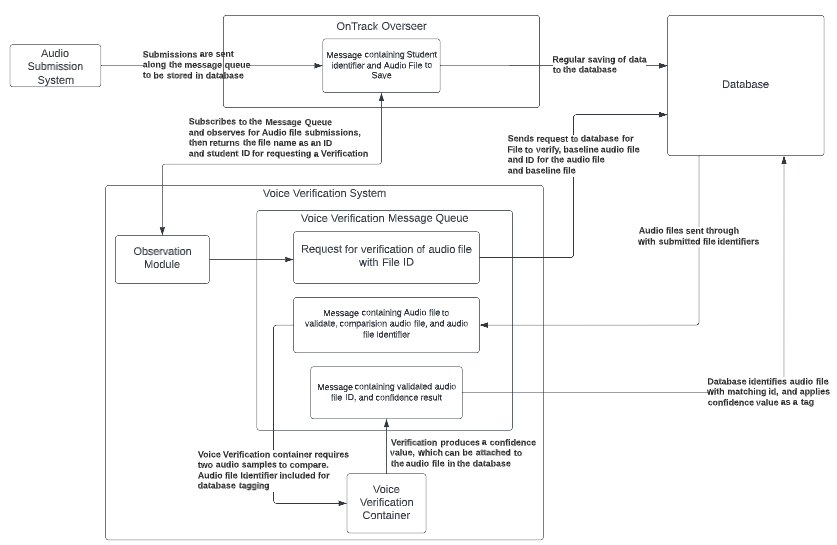
Data Formats
The Voice Verification system uses similar data formats to the OnTrack system. The audio files are stored in an SQLite database, attached to the OnTrack API. In the database, three new values are appended to audio submissions:
| Database Tag | Purpose | Possible Values | Example |
|---|---|---|---|
Verified | To determine if the file has already been verified | Boolean | True |
Baseline | To determine if this is the baseline file to verify new submissions | Boolean | False |
Confidence | Returned confidence values from verification. Number between 0-1. 0 if not yet verified. | Real | 0.87 |
These values are appended to the existing documents in the SQLite Database.
Data Flow
The messages in the Voice Verification Message Queue should follow the same structure as the OnTrack Overseer Message Queue. Requests to the database have the following parameters:
task_id: task associated with the submissionsubmission: path to the submission zip file or folderoverseer_assessment_id: id of the overseer message. used to keep track of individual assessments.
Messages to the Voice Verification system also contain a baseline parameter, which is the file
path to the baseline audio sample for that student.
Messages from the Voice Verification system have the following parameters:
task_id: task associated with the submissionsubmission: path to the submission zip file or folderoverseer_assessment_id: id of the overseer message. used to keep track of individual assessments.confidence: confidence value returned from the verification systemverification time: when the verification was completed.
These values are then appended to the existing documents in the SQLite Database.
User Interaction
Ideally, students wont no interaction with the verification system. Once an audio file has been submitted, it is automatically be queued for verification. Once verified, the assessor can listen to the audio submission, and view the confidence value.
Testing
Testing for the implemented system would must include the following strategies:
- Validation of files with the same speakers.
- Verification of files with different speakers.
- Verification of files with multiple different speakers.
- Verification of files with no speakers.
Additionally, other methods of bypassing the system should be investigated. This would include testing database security; more specifically where the validation results are stored.
Finally, testing different values for confidence thresholds would allow for more refined use of the voice verification system.
Success metrics
To measure the success of the system, a Confusion Matrix should be generated to determine the false positive and false negative rate of the system. As results would be validated by an assessor, this information can be tracked per assessor, and collated for review.